Configuration is code
In most major outages, there’s no flood in the data center, no massive DDoS, or some unknown vulnerabilities. Instead, someone “just” changes a configuration.
SOFTWARE ENGINEERING
1/4/20267 min read


Nature of a catastrophe
Catastrophic mistakes can happen. Even with the best of intentions there will be things that can and will go wrong. However off late some of those mistakes have in fact started happening once too often. Cloudflare (CF) for example had major outages twice within the span of a month, in Nov and Dec 2025. Google in Jun 2025, AWS had one recently, Facebook suffered a global outage a few years back as did Fastlys CDN around the same time.
When such events occur, they can lead to complete blackouts in certain regions and cause severe disruptions to services and products reliant on these platforms. This results in an unaccounted amount of business loss, affecting numerous industries and users worldwide.
So what causes some of the best technology companies to have these kinds of severe issues? After all they probably have the most cutting edge technologies in place.
Turns out the most dangerous code in your system is often the “just a config change” that bypasses normal engineering rigour.
Let us look at a couple of them to see if there is a pattern and possible solutions
Facebook’s global outage from a BGP misconfiguration (Oct 4, 2021)
What transpired...
Facebook's RCA stated that a chain reaction caused Facebook, Instagram, Whatsapp to go offline.
Here is what I gleaned
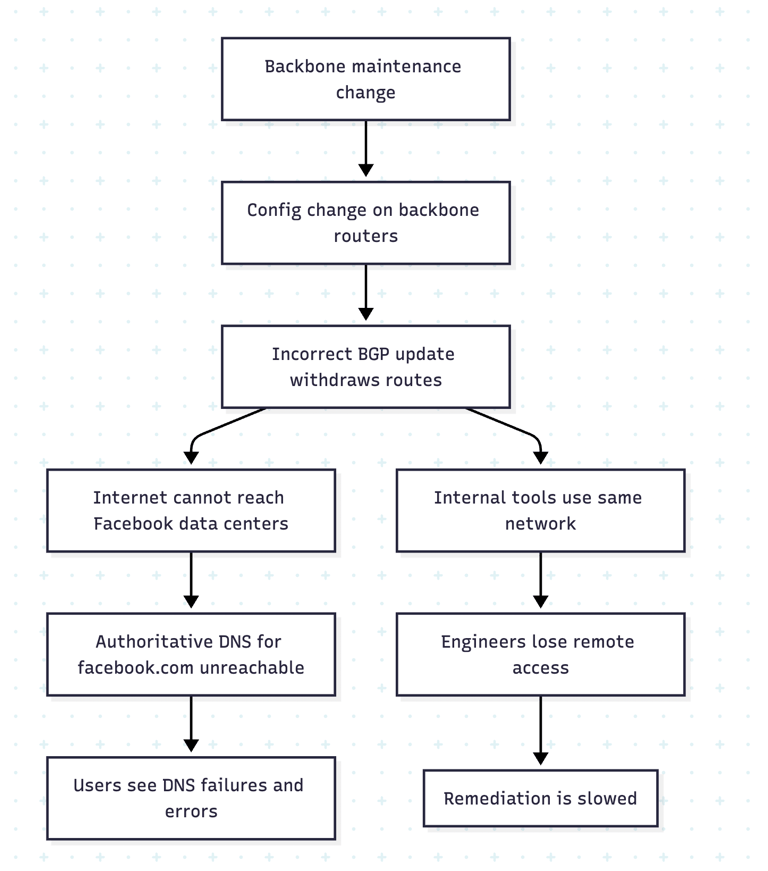
A maintenance operation on the backbone network included a configuration change.
This change unintentionally caused Facebook’s backbone routers to withdraw BGP routes announcing their data centers to the internet.
As a result, external DNS resolvers could not resolve .facebook.com, .instagram.com, etc., because.. ..
Authoritative name servers were unreachable.Not only that even Facebook’s internal tools and systems became inaccessible to engineers. It wasn’t just the production services—many internal control planes and access tools depended on the same network.
Root cause
A network configuration change (BGP) with insufficient safety checks effectively made Facebook’s infrastructure disappear from the internet and broke internal recovery tooling at the same time!
From the RCA I could distill the following key lessons:
Network changes (especially BGP) must be guarded by strong pre‑deployment validation and simulation.
Always preserve a break‑glass path to management and recovery systems that doesn’t depend on the same stack that might fail.
Consider dependency inversion: internal tooling for remediation should have fewer dependencies and more resilience than the systems they fix.
Build rate‑limiting and sanity checks into control plane operations (never withdraw all prefixes at once for eg etc).
Let us now turn our attention to a very recent one that happened on Nov 2025 with Cloudflare
Cloudflare's database change that caused a major outage (Nov 18, 2025)
What transpired...
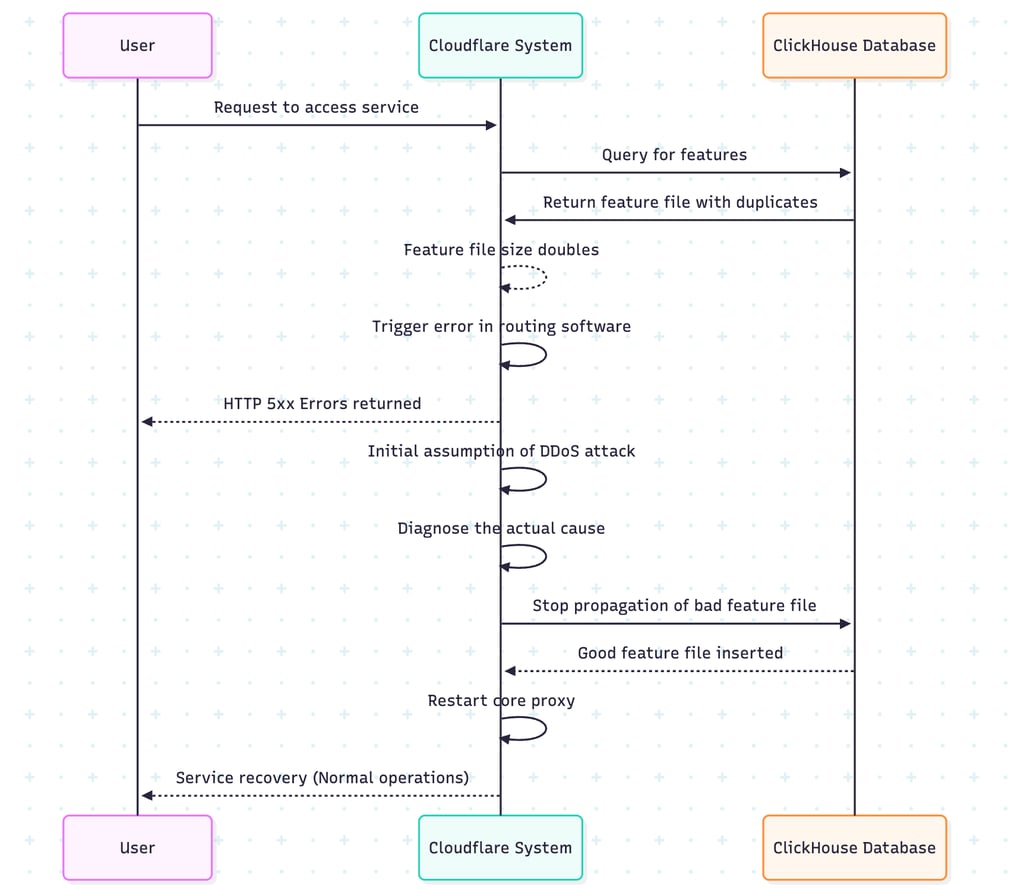
According to the Cloudflare post mortem Cloudflare recently experienced a significant outage due to a change in permissions in one of its database systems, which caused an error in its Bot Management feature. This error was not the result of a cyber attack, but rather stemmed from the generation of an oversized configuration file due to duplicated data entries. When this file propagated across Cloudflare's network, it exceeded the allowed size limits for internal software, causing failures in traffic routing and resulting in widespread service disruptions.
It would have looked something like what happened below - please note this is my interpretation of what transpired ...
Root Cause
The incident at Cloudflare (CF) was indeed triggered by a configuration change related to the permissions of the ClickHouse database system. Specifically, the change allowed queries to return metadata that included duplicates from underlying tables. This caused the feature configuration file used by the Bot Management system to contain an excessive number of entries, effectively doubling its size. The routing software had a pre-defined limit on the size of this configuration file; exceeding this limit led to a system error and resulted in HTTP 5xx error responses. To make things harder to diagnose because the bad file propagation itself took some time across the Clickhouse nodes sometimes the systems performed properly and at other times they failed making the engineers at CF think it was a DDOS attack.
Verbatim from the RCA:
"Bad data was only generated if the query ran on a part of the cluster which had been updated. As a result, every five minutes there was a chance of either a good or a bad set of configuration files being generated and rapidly propagated across the network."
Before getting into the lessons learnt lets also understand a little bit of how it would have impacted the overall network that connects to Cloudflare
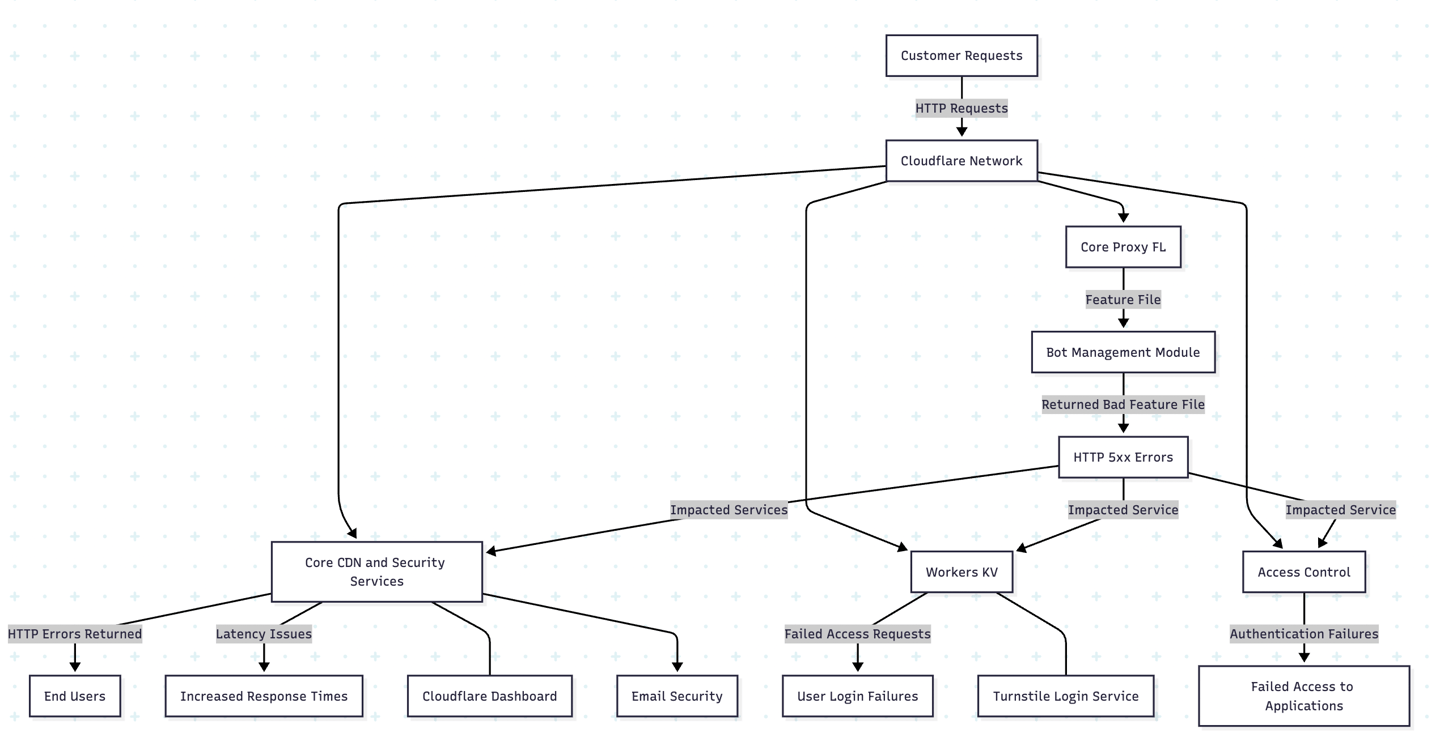
While from the RCA it comes across that the system design of CF is modular and robust, in this case the Core Proxy FL which is responsible for routing the requests got impacted. This bit is important.
Here's the deal : the bot management utilises a feature file and that feature file was incorrectly generated and that same feature file is used by the routing software which then started to malfunction. There perhaps is a needs for better safe guards in place when it comes to something as vital as the Core Proxy given the surface area of that entity is essentially the entire internet.
You see the change was made at one of the most fundamental layers (in this case a database) and the erroneous replication took its time thus causing the time to detect go be a lot longer.
Key lessons
The incident emphasises the need for rigorous oversight and validation of configuration changes, especially those that can impact critical systems.
There is a need to improve how the system handles unexpected errors. This includes implementing better fail-safes and ensuring that services can continue functioning even when certain processes fail.
Any changes made to database systems should undergo extensive testing to assess their impact on dependent services, particularly in distributed environments. ( I am personally unsure how this will scale)
Establishing Global Kill Switches: Implementing global kill switches can allow for the immediate disabling of features that are causing widespread issues, thus preventing further propagation of errors. This is the single most important aspect towards both resilience and damage control. CF has since accelerated its efforts towards what they are calling Code Orange which would try to limit the extent of the damage. This after they suffered another outage in December
Cross‑cutting patterns in config‑driven outages
Looking across these RCAs, the same patterns keep showing up.
1. Config is code (but often not treated that way)
While I have tried to cover Facebook and CF as examples it's a similar pattern if you were to look at the google outage or some of the others too.
Configuration changes that had unexpected performance or system behavioural impact.
Inadequate testing, review, or staging for those changes.
What needs to be done
Store configuration in version control with mandatory review.
Run configs through static analysis, linting, and unit tests.
Integrate config changes into CI/CD with automated validation.
2. The “Blast Radius” problem
Fast global rollouts magnify the cost of mistakes:
Cloudflare feature file change : A faulty change propagating from a core layer without proper checks was pushed out
Facebook BGP change: removed routes globally.
Google auth change: impacted every service relying on a central system.
What needs to be done
Default to canary rollouts: region by region, or small percentage of traffic.
Implement automatic rollback tied to health metrics and error budgets.
Define and enforce blast radius constraints in tooling (“this change may only affect X% of traffic initially”).
3. Centralised control planes as single points of failure
Auth systems, routing control, global configuration, and CI/CD are all high‑leverage components:
If they break, everything that depends on them suffers.
Outages get worse when the same systems power your recovery tooling.
What needs to be done
Harden control planes with separate SLOs, redundancy, and isolation.
Maintain out‑of‑band access paths (separate management networks, break‑glass accounts, independent DNS, etc.).
Turning RCAs into resilience
In today's digital landscape, catastrophic mistakes are an unfortunate reality, even for major providers. Companies like Cloudflare, Facebook, and Google not only publish RCAs as public relations damage control but also as essential learning tools. A recurring theme among these analyses is the often underestimated risk associated with seemingly simple configurations. These "just a config change" updates can bypass traditional engineering rigor and lead to significant issues.
To manage configuration safely, it's crucial to treat it with the same seriousness as code. Elevating configurations to first-class code status involves version controlling everything, from service configurations and WAF rules to routing policies and feature flags.
Storing all configurations in repositories like Git ensures proper tracking and history, while rigorous code reviews are essential for any modifications, especially for global rules and shared control planes like DNS or service mesh systems.
Testing and validation are non-negotiable. Static checks such as schema validation and policy checks help ensure safety, while dynamic checks in test environments allow for the application of configurations under realistic loads. Constraining the blast radius by design is another crucial principle, as single changes can have far-reaching effects. Implementing canary rollouts, starting with a small percentage of traffic, and expanding only if metrics remain healthy can mitigate this risk. Gradual expansion with built in guardrails can further reduce potential damage.
Scoping configurations on a per-customer or per-region basis adds another layer of protection. Risky rules should be gated behind feature flags and gradually enabled. Strengthening central control planes is vital as they have a significant blast radius. These should be built with critical infrastructure standards, including strong SLOs, redundancy, and independent failure domains.
Reducing dependencies and ensuring control planes are self contained is crucial for stability. Implementing out-of-band access and "break glass" emergency paths provides fail-safes during outages. Automation of safety checks through tools that review impact before changes are made can prevent potential errors. By employing pre change impact analysis and simulators, organizations can anticipate the effects of changes before implementation.
Finally, learning continuously from both public and internal RCAs is critical. Avoiding the reinvention of the wheel by analyzing others' mistakes helps refine and improve processes, ensuring that when mistakes happen, they become valuable learning opportunities rather than repeated failures.