Systems will degrade
How to go about mitigating incidents on production and reducing adverse impact.
SOFTWARE ENGINEERINGINCIDENT MANAGEMENT
7/29/20235 min read
Incidents are inevitable
Incidents are inevitable. If you want an incident free production environment then do not deploy your software!
The idea really is to minimise the frequency of incidents that can happen and over time reduce the amount of time that each incident takes.
To achieve this there are 4 major areas that a successful organisation should look at
Culture
I start with culture because it often gets overlooked, and if not handled correctly, it can lead to significant undesirable side effects that ultimately result in suboptimal systems.
Incidents are unpleasant—there’s no two ways about it. However, it’s crucial for the team to adopt a blameless approach to understanding why the incident occurred. This mindset aids in reaching accurate root cause analysis (RCA), which in turn fosters the right kind of organisational learning. A culture that promotes teamwork can be highly effective; I have worked at companies that took pride in sharing their RCAs. Unsurprisingly, these companies tended to have some of the most robust systems I have encountered.
Metrics
Incidents can lead to considerable heartache. Often, people become emotional about why things are breaking, and even when the right efforts are in place, perception can create a sense of inadequate progress. Without appropriate metrics, you would be shooting in the dark regarding which incidents should be prioritized.
When it comes to metrics, I prefer to keep it simple. There are two primary metrics to focus on:
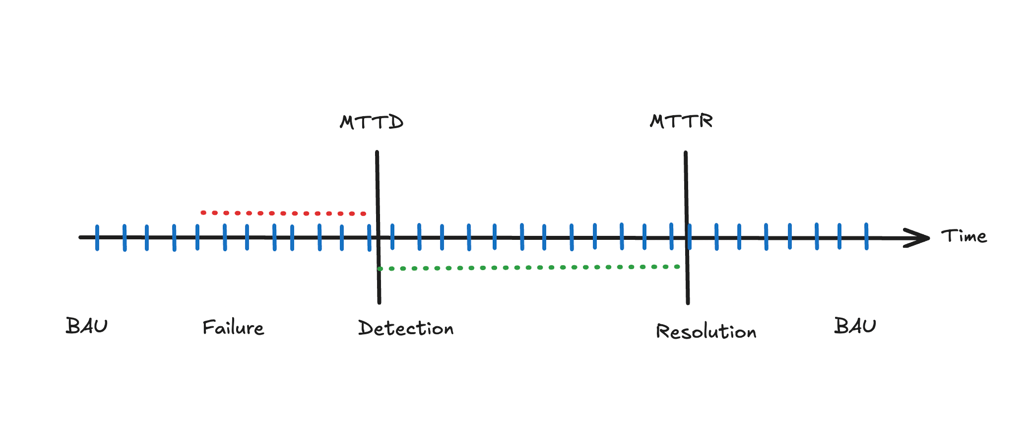
Mean Time to Detect (MTTD): This measures the average time taken to detect incidents within a specific time period. This metric is essential because your engineering team should be the first to know if something is going wrong, and more importantly, where within a complex system the failures are most prevalent.
Mean Time to Resolve (MTTR): This metric measures the average time required to resolve an incident once it has been detected. The objective is to continually reduce the MTTR over time. Achieving this often involves various action items, which, when correctly identified and implemented, can significantly reduce the overall impact of an incident.
In addition to these technical metrics, I also recommend considering domain-specific business metrics. For example, in a warehouse management system, this could include delays in outbound operations. In order management systems, you might measure order losses and the recovery period. The actual impact of incidents can be quantified using the formula: Actual Impact = Orders Lost - Recovery Period. In logistics, one might track the number of Service Level Agreement (SLA) breaches. Being objective in business metrics enables engineers to relate to and take ownership of domain.
Governance
Organisations approach governance differently. Some have a federated approach, where individual teams are responsible for handling issues themselves, while others have a more centralized structure with a central team handling governance.
I recommend a hybrid approach where a central team is responsible for setting and driving standards while allowing individual teams to implement these standards. Established standards should cover aspects like proper documentation, ensuring that RCAs are detailed, and making sure that action items from those RCAs are followed through.
This governance team would also track its own metrics. As patterns emerge from the data, this team would be responsible for developing various tools to enhance predictability and velocity across the organization.
Tooling and Deployment Strategies
The governance team above would also be responsible for development and ensuring that necessary tools are built which help in better predictability.
Below is a comprehensive list that I found useful, but by no means is it a complete list. You can refer to some of them if it helps you.
Monitoring Tools:
Application Performance Monitoring (APM): Tools like PerceptInsight, New Relic, Datadog help track application performance, identify bottlenecks, and alert on anomalies.
Infrastructure Monitoring: Tools like Prometheus, Grafana, and Nagios monitor the health of servers, networks, and other infrastructure components.
Log Management:
Tools such as ELK Stack (Elasticsearch, Logstash, Kibana), Splunk, and Graylog help in aggregating, searching, and visualizing logs to troubleshoot issues quickly.
Incident Management:
Platforms like PagerDuty, Opsgenie, and ServiceNow facilitate incident response and management, helping teams respond to incidents more effectively and track trends over time.
Error Tracking:
Tools like Sentry, Rollbar, and Raygun help capture and analyze errors in applications, providing insights into performance and user experience issues.
Automation and Orchestration:
Infrastructure as Code (IaC) tools like Terraform and configuration management tools like Ansible and Puppet automate environment setups and ensure consistency, reducing human error.
Testing and Continuous Integration/Continuous Deployment (CI/CD):
Jenkins, GitLab CI, and CircleCI help automate testing and deployment processes, allowing for early detection of issues before they reach production.
Capacity Planning and Load Testing:
Tools like Apache JMeter and LoadRunner simulate traffic and monitor application performance under stress, helping identify weaknesses before they lead to incidents.
Security Tools:
Implementing security monitoring with tools like Snyk and OWASP ZAP can catch vulnerabilities early, preventing security-related incidents in production.
Backup and Recovery Solutions:
Ensure data integrity and availability with tools like Veeam or AWS Backup to handle data recovery and minimise downtime in case of incidents.
Deployment Strategies: Canary and Blue-Green
Canary Deployments:
As previously mentioned, this deployment strategy gradually rolls out new code to a small segment of users. It allows teams to monitor the canary user group closely with tools like Percept Insight to detect any issues early.
This helps gauge the impact of new features before a full-scale rollout.
Blue-Green Deployments:
In this strategy, teams maintain two identical production environments (blue and green). The new version is deployed to the inactive environment, and thorough testing can occur while the current version continues to serve users.
Once verified, traffic can switch from the old version to the new version seamlessly, minimising downtime. Monitoring through Percept Insight helps ensure that any performance discrepancies can be quickly detected after the switch.
Benefits of these Strategies
Both canary and blue-green deployments significantly reduce the risk of production incidents by controlling how changes are introduced and ensuring stability through testing before full-scale implementation.
These methods enhance testing in production by allowing real user data to validate new features or versions while reducing disruption.
Incorporating these deployment strategies alongside robust monitoring solutions like PerceptInsight can greatly enhance the reliability of applications in production and help in managing incidents effectively.
Conclusion
In summary, while incidents in production environments are unavoidable, organisations can significantly reduce their frequency and impact through a comprehensive approach that encompasses culture, metrics, governance, and tooling. By fostering a blameless culture, teams can focus on learning from incidents to create a more resilient system. Establishing clear and simple metrics such as MTTD and MTTR enables organisations to track performance and prioritise efforts effectively.
Implementing strong governance structures ensures that best practices are maintained throughout the organisation, while the right tooling and deployment strategies, such as canary and blue-green deployments, enhance predictability and minimise disruptions.
Ultimately, the combination of these elements not only promotes a more reliable production environment but also cultivates a culture of continuous improvement and collaboration. By committing to these practices, organisations can navigate the challenges of operational incidents more effectively, ensuring greater stability and success in their production systems.